
Tech
Il nostro viaggio è giunto al termine: Flowe interrompe l'offerta dedicata ai Privati. Leggi qui.
07 novembre 2023
di Marco Santoni

Per poter ottimizzare i costi di job streaming con Databricks, abbiamo identificato le due seguenti aree di miglioramento, pur mantenendo (o talvolta addirittura migliorando) l'affidabilità e la manutenibilità dei nostri job:
In questo articolo raccontiamo i dettagli di questi interventi, fornendo innanzitutto alcune informazioni sul nostro punto di partenza.
In Flowe usiamo Databricks per eseguire i nostri job di elaborazione dati su Apache Spark. I nostri job streaming Spark hanno due obiettivi principali:
I job streaming di Spark possono avere un costo se non si presta attenzione alla configurazione del job perché il prezzo del consumo di risorse potrebbe presto aumentare.
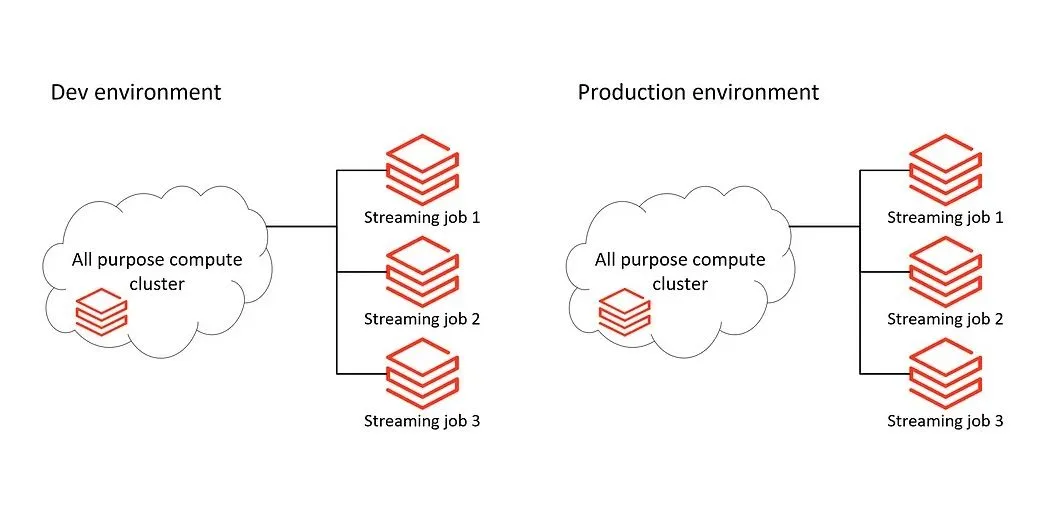
Inizialmente, abbiamo progettato i nostri job di streaming come singoli job in esecuzione su un cluster all-purpose. I job venivano eseguiti tutto il giorno, sia in ambienti di sviluppo sia di produzione e quindi anche il cluster era attivo continuamente.
Siamo partiti dalla seguente domanda: abbiamo bisogno di dati in tempo quasi reale anche nell'ambiente di sviluppo?
Nel nostro caso, la risposta è stata "no". Per le nostre necessità, sarebbe andato bene un job di streaming in esecuzione una sola volta al giorno nell'ambiente di sviluppo. Questo job si sarebbe fermato una volta che tutti i nuovi dati del giorno precedente fossero stati elaborati.
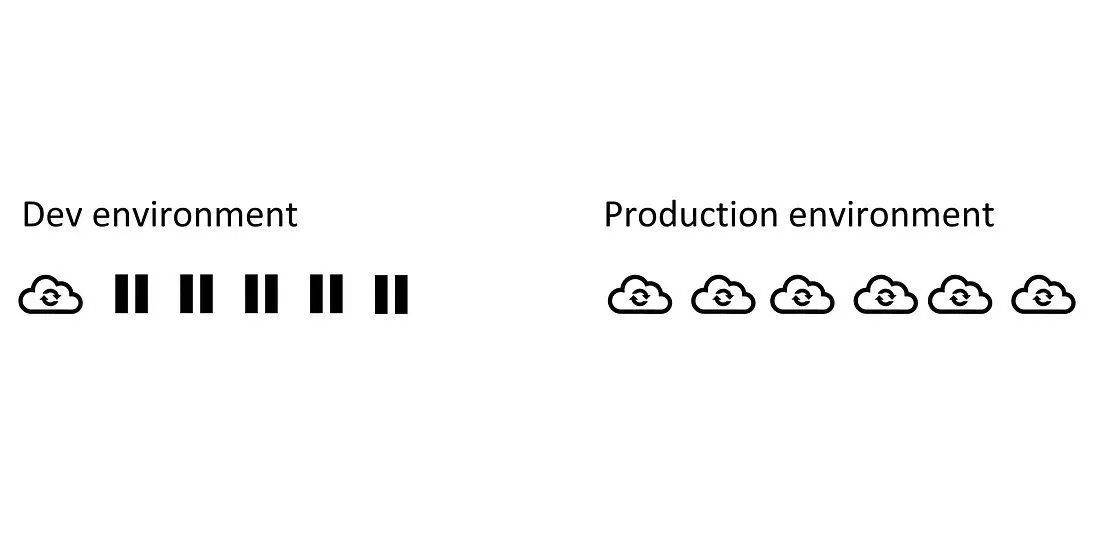
La nostra sfida è stata quella di ridurre il tempo di esecuzione nell'ambiente di sviluppo, mantenendo la configurazione del job e del codice il più semplice possibile. In altre parole, volevamo che il nostro codice fosse pulito e che non contenesse logiche dettate dalla decisione di avere una configurazione di schedulazione diversa in ambienti diversi.
Come avere un codice di streaming Spark che viene eseguito una sola volta sui nuovi dati nell'ambiente di sviluppo, ma che continua a essere eseguito in produzione?
Abbiamo deciso di combinare l'uso della modalità di trigger availableNow e della configurazione continuous del job Databricks.
(
df
.writeStream
.format("delta")
.outputMode("append")
.option("checkpointLocation", STREAMING_CHECKPOINT_LOCATION)
.trigger(availableNow=True)
.toTable("tableName")
)
È possibile specificare la modalità di attivazione dello streaming del job. Scegliendo la modalità availableNow, la query di streaming elaborerà tutti i nuovi dati disponibili e poi si fermerà da sola. Questa modalità risulta adatta all'ambiente di sviluppo. È sufficiente specificare l'ora del giorno in cui si desidera avviare il job. Quindi il job elaborerà tutti i nuovi dati disponibili e si fermerà fino all'esecuzione del giorno successivo. Il seguente file JSON è tratto dalla configurazione del job per l'ambiente di sviluppo.
{
...
"schedule": {
"quartz_cron_expression": "0 0 1 * * ?",
"timezone_id": "UTC",
"pause_status": "UNPAUSED"
}
...
}
E per quanto riguarda la produzione? Invece di definire una schedulazione, possiamo configurare il job con un trigger di tipo “continuous”, che assicura che un'istanza del job sia sempre in esecuzione. Se una run termina, ne inizia una nuova immediatamente dopo.
Nota Bene: per un job in streaming, questa scelta potrebbe aumentare leggermente la latenza dell'elaborazione dei dati. Se questa latenza non è un problema per il vostro scenario, ciò vi permetterà di avere un codice pulito da qualsiasi configurazione dipendente dall’ambiente e di ridurre il tempo di esecuzione negli ambienti di sviluppo o di test.
La scelta di una migliore configurazione del cluster ci ha permesso di ottenere il risultato migliore con il minimo sforzo. Lavorare con cluster all-purpose comporta un maggiore costo computazionale che, se il cluster è dedicato solo all’esecuzione di job automatizzati, può essere evitato. Abbiamo spostato i nostri flussi di job su cluster di tipo job-compute che garantiscono risorse più economiche a parità di dimensioni di calcolo.
In conclusione, abbiamo apprezzato che l'adozione di cluster di tipo job-compute:
Lo stesso file JSON che definisce la configurazione del job ora ospita anche la definizione del cluster. Gli sviluppatori beneficiano quindi della possibilità di avere un settaggio esplicito della pianificazione e dell'infrastruttura nello stesso punto. È persino possibile raggiungere livelli elevati di regolazione fine, abbinando diversi dimensionamenti del cluster a diversi task nello stesso job.
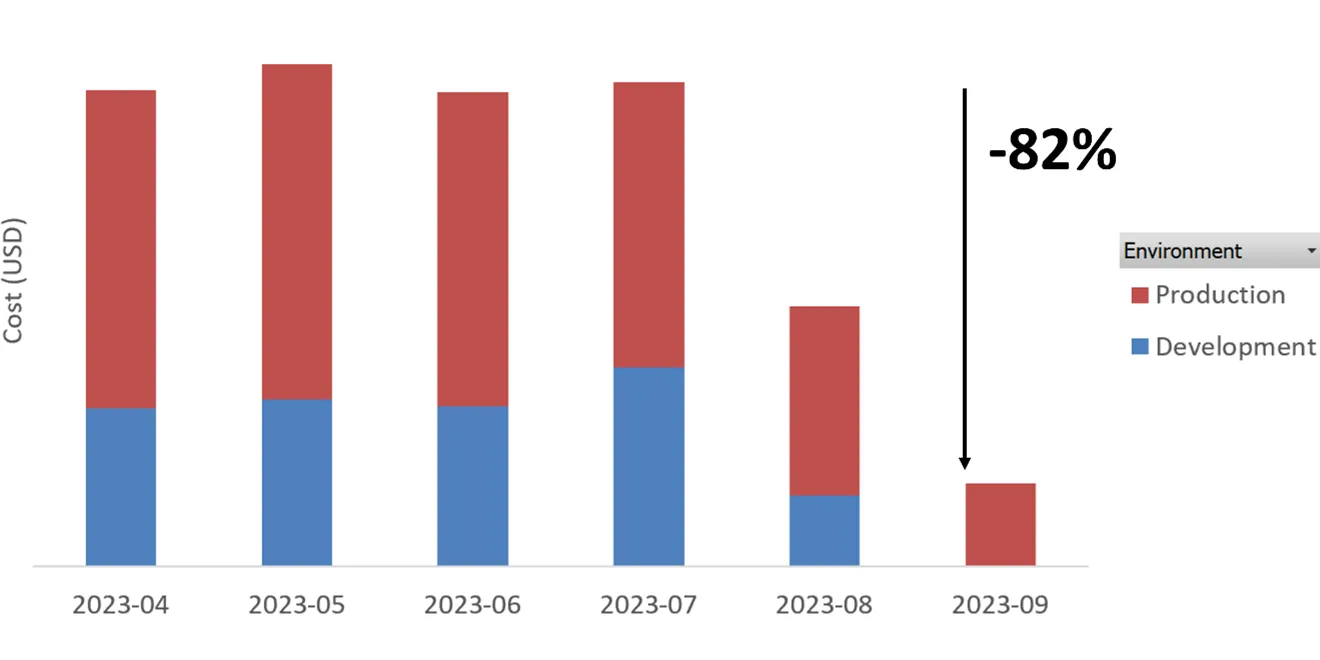
Nel corso del mese di agosto 2023 abbiamo rilasciato i miglioramenti descritti in questo articolo su un job streaming. Abbiamo quindi misurato il consumo di DBU (Databricks Unit) mensile espresso in dollari. A fine settembre possiamo quindi analizzare i risultati dell’intervento.
Abbiamo ridotto complessivamente i costi dell’82% rispetto alla configurazione precedente del job streaming. La riduzione più significativa si rileva, come atteso, nell’ambiente di sviluppo dove l’esecuzione del job è stata ridotta a pochi minuti al giorno.

